
Covid-19: Facilitating Remote Work, “almost free”.
 The rapid proliferation of Covid-19 has necessitated deepening concessions here in Canada and all over the world. Starting with social distancing, gathering limits, and as of today in Ontario, all non-essential businesses ordered to close. A lot of businesses have already voluntarily closed, but today marks the first time in my lifetime that our government has ordered all businesses to close. The exception being the rebel shops that used to stay open on Sundays and Holidays when I was a child, but it’s not just shops today.
The rapid proliferation of Covid-19 has necessitated deepening concessions here in Canada and all over the world. Starting with social distancing, gathering limits, and as of today in Ontario, all non-essential businesses ordered to close. A lot of businesses have already voluntarily closed, but today marks the first time in my lifetime that our government has ordered all businesses to close. The exception being the rebel shops that used to stay open on Sundays and Holidays when I was a child, but it’s not just shops today.
This announcement will no doubt accelerate lay offs, business closures, and increasing uncertainty about what the next few months will look like for all of us. One thing is certain, failure to accept this new reality will result in its prolonged presence. The sooner we all take measures to cut the transmission rates the sooner we’ll be on the other side of it.
Revenni acknowledges that we’re in a privileged position as 80% of our work happens online. We’ve had the requirement to work from anywhere for years and we don’t expect a lot of impact to our daily operations. This isn’t true for a lot of small businesses, so today we are announcing that we will assist you and your small business get setup for remote work – “almost free“.
What does “almost free” mean? It means that we will donate our labor and resources to your small business in exchange for a small monetary donation to The Sick Kids Foundation. There are a couple of requirements.
- We define a small business as a company with fewer than 15 employees. You should be one.
- Proof of donation in the amount of $50 CAD is required, and must be dated after March 23rd, 2020.
- You have some on prem infrastructure capable of running Linux or are willing to pick up a raspberry pi in order for us to deploy a solution for you.
- We cannot guarantee timeline for deployment, but we’re pretty seasoned at this so it shouldn’t take too long. Of course, timing also depends on the number of requests we receive. We’ll do our best to get you up and running as soon as possible and update this post if we get overwhelmed.
What does our solution look like? It’s a tried and true deployment of OpenVPN. OpenVPN will allow your staff to connect to your on prem infrastructure and make use of those resources as if they were physically in your office.
Please fill out the following form if this offer appeals to you.
Revenni is a Toronto based IT consulting firm specializing in Linux System Administration, Linux Consulting, Managed Linux Services, and 24×7 Emergency Linux Support.
Configuring Hitch to Terminate SSL for Varnish
Varnish is an HTTP accelerator (cache) application. We make heavy use of Varnish here at Revenni and recently started deploying it alongside Hitch.
Varnish is designed to sit in front of your web server and have all clients connect to it. You configure your web server as a backend to Varnish, when a client requests a document Varnish will retrieve the document from the webserver and keep a copy of it in memory. When the next client requests the same document, Varnish serves it directly from memory instead of hitting your webserver and therefore middleware/database/disk.
The one glaring “problem” with Varnish is that it was built specifically to avoid SSL support. You can find the full story on that decision here and here.
HITCH TO THE RESCUE
“Problem” solved.
Varnish Software has developed Hitch, a highly efficient SSL/TLS proxy in order to terminate SSL/TLS connections before forwarding the request to Varnish. Hitch supports tens of thousands of connections and up to 500,000 certificates on commodity hardware.
Hitch does one thing and does it incredibly efficiently. We have also used NGINX in order to terminate SSL connections before proxying to Varnish. That worked very well and we still support that configuration for a lot of clients.
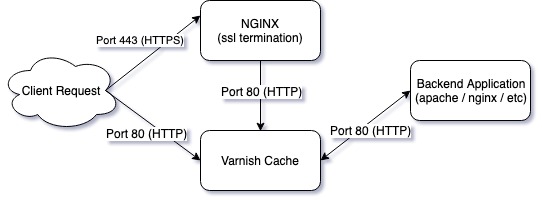
Hitch fits exactly where NGINX did in the chart above.

So how do you get started?
1. INSTALL HITCH
Compiling Hitch from source will get you the latest features including TLS 1.3 and unix domain sockets for Varnish communication. We’re going to cover Hitch 1.4.4 which is in the Ubuntu LTS (18.04) repository.
2. GENERATE HITCH.CONF
Hitch installs without any configuration. You can copy the example configuration from /usr/share/doc/hitch/examples/hitch.conf.example to /etc/hitch/hitch.conf, or use our slightly modified version below.
3. ENABLE HITCH
To summarize below starting hitch:
- Hitch will listen on all ip addresses, on port 443
- Hitch will terminate SSL/TLS for all certificates using SNI and pass them to varnish on port 6086
Revenni is a Toronto based IT consulting firm specializing in Linux System Administration, Linux Consulting, Managed Linux Services, and 24×7 Emergency Linux Support.
Cloud Contingency When The Ban Hammer Drops
We design and support a lot of deployments on a wide variety of platforms. Our clients are dispersed across Linode, Vultr, Digital Ocean, OVH, and AWS, which are all great platforms in their own right. They all have their different pros and cons; however, one thing they all share is automation built by fallible humans with good intentions. Hopefully, you won’t be on the receiving end of those automated erroneous decisions, but what if you are? Enter Cloud Contingency When The Ban Hammer Drops.
This article is inspired by the recent lockout of Raisup, an AI startup based in France.
How @DigitalOcean just killed our company @raisupcom. A long thread for a very sad story. pic.twitter.com/uOFCDRoYJ6
— Nicolas Beauvais (@w3Nicolas) May 31, 2019
The long story short is that some bad logic in some of Digital Ocean’s anti-abuse automation triggered and took Raisup’s entire infrastructure offline. Adding to the crisis, the Digital Ocean support/review process failed miserably, and Raisup had to resort to twitter for resolution after ~30 hours of downtime.
Unfortunately, we’ve had to deal with this exact scenario, and many along the same lines for several of our clients as well. Never with Digital Ocean, but definitely with other providers mentioned above. The point is, your entire company is one arbitrary decision away from being locked out of your resources with lengthy resolution time and possibly no resolution – if Raisup didn’t have 5000 followers on Twitter and the power of social media, the resolution could have taken significantly longer.
So what’s the solution here? Always have your data backed up with a third-party vendor, also known as, an off-site backup. Every cloud or VPS provider has some backup option. It’s easy to think that your data is safe because their automated backup service has copies of your data. This doesn’t consider the fact that they could have a colossal failure rendering your backups unusable, or in this case, an account lockout making them completely inaccessible. At one point, Nicolas tweets: “Please, @digitalocean, @markbtempleton, @barryjcooks, @benuretsky, @moiseyuretsky give us at least access to our backups to save our company.”
When you’re a small organization, it can be challenging to consider all of the liabilities on the system side while also creating your product/service at breakneck speeds. You perform your due diligence and take your providers at their word that they’ll hold up their end of the bargain. Despite their best efforts, sometimes an unfortunate series of events leads to them not doing so.
At Revenni, we make use of restic. Restic is an opensource incremental/dedup backup solution that is simple to set up, encrypts your backups, and can store them on a myriad of storage backends including most major cloud providers. We store tens of terabytes of encrypted backups on Backblaze B2. Backblaze has been around for over a decade providing backup solutions to consumers and businesses alike. In 2015, they released Backblaze B2, an object storage platform at a fraction of the cost of compatible alternatives ($0.005/GB/mth or $5.00/TB/mth) .
We’re going to show you how you too can have offsite backups providing business continuity should you find yourself on the receiving end (deservedly or not!) of a ban hammer or complete destruction of your cloud providers working dataset and backups.
1. OBTAIN A BACKBLAZE B2 ACCOUNT
Head over to B2’s signup page and create an account. Once logged in, you’ll see a giant “Create a Bucket” button. Click it.
2. CREATE YOUR FIRST BUCKET
You’ll have to specify a globally unique name for your bucket, so we recommend prefixing the bucket name with either your company name or other unique string.
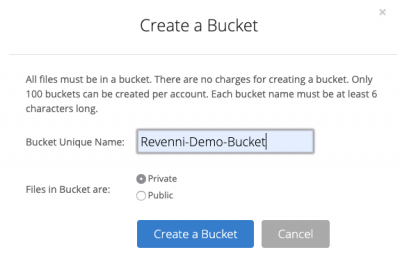
Once you click “Create a Bucket”, you’ll see the bucket listed on the Buckets page.
3. CREATE A BUCKET SPECIFIC APP KEY
Now that we have a bucket created, we need to create a bucket specific App Key. This key pair will allow restic to access this individual bucket and none of the others in your account.
Click App Keys on the left menu and on the resulting page click the “Add a New Application Key”.

On the resulting dialog, we specify a key name and restrict the key to the “Revenni-Demo-Bucket”.
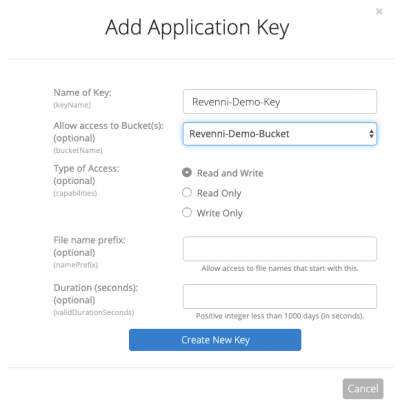
Click Create New Key.
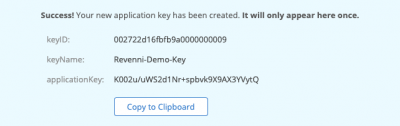
You will be shown the keyID, keyName, and applicationKey. Record these, they will not be shown again. Don’t post them on the internet as we did below, this bucket no longer exists.
4. INSTALL RESTIC
Restic packages in official repositories lag behind their development cycle. We recommend installing restic via their Official Release Binaries. Download the correct file for your operating system, most of you will download restic_0.9.5_linux_amd64.bz2, and if not, you’ll likely know which to download.
5. CREATE RESTIC KEY & SCRIPT
Restic needs a very small amount of configuration. We create a restic directory, and restic encryption key. The restic.key file contains the passphrase used to encrypt data before storing it at B2. Without this key, your backups cannot be restored on another server.
All of these commands are run as root.
Create /restic/restic.env with the following content. This file contains the repository location and credentials to access it.
The RESTIC_REPOSITORY is a string comprised of “b2:<bucketName>:<hostName>”. We use the hostname as the repository name.
Create /restic/restic.sh. This file sources the configuration in /restic/restic.env at runtime in order to store data in our B2 bucket.
Set restrictive permissions on /restic and it’s contents.
6. INITIALIZE THE RESTIC REPOSITORY
Restic needs to initialize the repository on the B2 Bucket. We stored our bucket configuration in /restic/restic.env. Any time you run restic commands directly your must first source this file so that restic knows where our repository is and what keys are required to access it.
7. RUN YOUR FIRST BACKUP
Everything is in place for us to take our first snapshot of the system.
8. SCHEDULING AUTOMATIC BACKUPS
Now that restic can backup our system when invoked with /restic/restic.sh, we should add a cron so that it runs every day at midnight and mails the results to the address specified in the MAILTO variable. Create /etc/cron.d/restic with the contents below.
8. GENERATE ARCHIVE FOR RESTORE
Now that we have restic snapshotting our system every night at midnight, we’ve checked off the offsite backup box.
Let’s create an archive so we can just extract it on a new machine and start the restore process.
Save this archive in a safe place. It’s not critical so long as you have the B2 keys and the Restic encryption key, but it will save you a lot of time setting up restic again.
9. SETUP RECOVERY MACHINE
So what happens if we cannot access our resources (servers and backups) from one provider?
We provision servers at our new provider and install restic on it (same process as step 4).
Copy the restic.tar.gz archive we generated to the new server and extract it. You’ll want to be in / when you do it.
9. START RECOVERY PROCESS
Restic allows us to mount our B2 Bucket using fuse. We can use this option to selectively copy data from our snapshots into the proper places on the system. You’ll need two terminals or a screen session.
In a second terminal you can now navigate the snapshots via standard linux commands.
Alternatively, you can copy data from the snapshot non interactively by running something like the following. A note about this method is that the path listed is “/” because we initially backed the system with / as the path.
The directory we’re restoring is specified by the –include directive, in this case, /important-data.
For more examples, see the restic restore documentation.
That’s it, restic in a nutshell for the masses.
Feel free to contact us if you have any challenges with setting up restic. We won’t even try to sell you something, we just want everyone to have options in the scenario that inspired this post. If you’re interested in our Ansible playbook we can post that too, this article is written so that functional backups can be had by all regardless of skillset.
Revenni is a Toronto based IT consulting firm specializing in Linux System Administration, Linux Consulting, Managed Linux Services, and 24×7 Emergency Linux Support.
Keeping Multiple Devices in Sync via Unison
There are two types of digital nomads, those who have a single workhorse device and those who have several. This post covers the challenges faced by the latter type.
When I’m in the office I have a MacBook connected to a 34″ ultrawide monitor. This is where most of my work is done as it offers the best user experience. Lots of screen real estate, comfortable ergonomics, and perfect for long sessions. In the field, I have another MacBook that is a lot less enjoyable to use with it’s 13″ screen placed on random surfaces with the worst ergonomics and posture.
One of the challenges I face is synchronizing work in progress, ssh keys, and gpg keys between my devices. It’s been a problem for years and I’ve had several solutions, but none quite as elegant as Unison.
UNISON
I discovered Unison when looking for an option to synchronize WordPress data across several machines serving a very high traffic site. Normally we’d use an EFS volume or deploy an NFS server, but both of those weren’t options for that client.
Unison is described as:
Unison is a file-synchronization tool for OSX, Unix, and Windows. It allows two replicas of a collection of files and directories to be stored on different hosts (or different disks on the same host), modified separately, and then brought up to date by propagating the changes in each replica to the other.
As advertised, I can sync my devices before leaving the office and take all of my work in progress, ssh keys, and gpg keys with me in the field. Once I return, with a single command I sync all of my progress in the field back to my office computer.
1. INSTALL UNISON
This process will differ depending on your operating system / Linux Distribution. Unison has to be installed on all machines that will be synchronized. The machines do not have to be running the same operating system, but you’ll have to set your paths correctly. More details in the comments of the Unison profile.
MacOS: I prefer to use Homebrew. If you do not have Homebrew setup, run the ruby command in a terminal to install it.
Debian/Ubuntu: Packages are available in both official repositories and the snap store.
2. UNISON PROFILE
Unison can be run completely from the command line and it also supports “profiles”. A profile is simply a set of parameters in a configuration file so that we don’t have to type out long error prone commands to sync our data.
In this scenario, the profile lives on the office computer in ~/.unison/.prf. The mobile laptop does not have a profile and all synchronization events are triggered on the office computer. An example profile, we’ll call it laptop,prf, it below and should be copied to ~/.unison/laptop.prf. Things you’ll want to modify in this profile are potentially:
- servercmd This is the path to unison on the laptop.
- root The first root entry points to the directory on the office machine containing the data we want to sync. We’ll specify exactly what to sync with path directives below. The second root entry is where our defined paths will be synchronized on the laptop. You’ll want to change the IP and path no doubt, but take careful note of the double forward slash (//), it’s not a typo.
- path The path directives specify what files or directories within the root that we want to copy. As mentioned, I want my repositories, gpg keys, passwords, and ssh key data.
- backupdir Specifies the directory in which the sync backups will be stored. This is relative so that it can be the same on mixed environment deployments (MacOS/Linux). It will be located in the root specified above.
3. SYNCHRONIZE YOUR DATA
Before we synchronize your data there are a few things to note.
- Synchronization is always initiated by the office computer, even when the laptop has the most current data.
- Due to our prefer=newer setting, any files that exist on both the office computer and laptop machine will be replaced by the newest copy.
- In order to avoid potential overwrites, I suggest that the data only live on the office computer for the first synchronization, after that you can freely update content on either machine and be confident that Unison will update both of them with the newest files.
- We tell unison to load the profile we created by specifying it (minus the prf extension) as the first argument.
Revenni is a Toronto based IT consulting firm specializing in Linux System Administration, Linux Consulting, Managed Linux Services, and 24×7 Emergency Linux Support.
Launching the Open SysAdmin Series
Revenni has started a new series of articles dubbed “Open SysAdmin.” But first, a little story.
Twenty years ago on an IRC network long forgotten, a group of like-minded individuals were hacking away trying to get Creative Sound Blaster cards working on a Linux machine so that we could play our favourite MP3s in x11amp. After the music came 3DFX VooDoo2 cards, and of course, Quake. Back then running Linux was a little bit different than it is today. Almost nothing worked out of the box. There was next to no documentation outside of a kernel module text file. We spent weeks participating in low-level development mailing lists trying to get the simplest things working. IRQs, IO addresses, everything was mapped manually and set via physical jumpers on the actual hardware. If this sounds like a foreign language to you, don’t worry, you’re not alone!
In the spirit of Open Source and Community, these efforts inspired us to create a Linux help site.
By combining each area of our expertise, we had all the bases covered, server deployment (no clouds then. VPS providers? Ha! nope.) on physical hardware, server administration, frontend development and design, technical writing, you name it. Over time our site grew from a boutique source of documents on compiling the kernel, LAMP (Linux Apache MySQL and PHP) stacks, mail, news, and ftp services to a real destination for thousands of people daily. We expanded from just IRC to web forums, starting syndicating news from other sites, and created our own syndication feed.
Archive.org capture of our origin. Circa 2000.
Everyone in our group went on to have very successful careers at some amazing tech companies. A few of us now run our own Linux consulting firms.
We’re celebrating Revenni’s first anniversary by revisiting our roots.
The Open SysAdmin series is a collection of howtos, scripts, and documents that we publish to give back to the community. We have dedicated our careers to Open Source Software and firmly believe in sharing as much as possible.